
At TimeLog, we are rapidly moving into a situation where we need to discuss how we will keep up customer growth, both in terms of new and existing ones. TimeLog is a single-tenant web application, so we scaling both horizontally and vertically. However, our monolith of an application requires us to scale for peaks. It is all good and well, but it puts an overhead on the cost of operation. Currently, I am looking into ways for us to 1) reduce peaks on our main servers, and 2) allow us to dynamically scale even higher when our customers are super active.
The peaks at TimeLog happens around month end where our customers build invoices based on the time registrations, and even more so in January where our customers analyses the last year and consolidating numbers to their ERP. Additionally, we see peaks when salary managers work out vacation and salary compensation packages.
Microservices are still a hot topic, and for good reasons. I have used a couple of days venturing into the possibilities of TimeLog utilizing microservices and a message queue to break down our monolith – or at least release it from some of its burdens. To be honest, I don’t see us breaking our monolith in the foreseeable future, and right now I don’t think we need to. More about that later.
Firstly in order to scale outside the actual application, we need a reliable message queue. This is the enabler for microservices. The message queue serves as a communications channel as well as a buffer. We put messages on it, it stores them for a given period of time and we can read messages from it and carry out the work. Service Bus, Message Queue, Distributed Streaming Platform, Event Hub, Event Grid. It comes in various flavors, each with different capabilities and options. There are a few terms that I found useful to describe:
- Events – Lightweight, a notification that something happened, no expectation on how it is handled, primarily for telemetry and data streaming
- Messages – Raw data, fixed expectation on how it is handled, primarily for transactions
- Topic – Categorizing messages/events in the queue
- Partition – Logical categorization on the server
As TimeLog is mainly driven by Microsoft technology, it was naturally for me to start looking into the possibilities in Azure. Microsoft have documented nicely how to compare the different messaging options. Summarized: Azure Event Hubs are for events (fast, at least once, no sorting), Azure Event Grid is for events (serverless, at least once, no sorting) and Azure Service Bus is for messages (heavy on config, but has all options). For completeness, Apache Kafka is for events. A found a few good comparison posts.
There are a few interesting attributes to consider for a message queue:
- Messaging guarantee – At-least-once delivery is the supported by all the services and is easy to understand. This should also work for TimeLog.
- Ordering guarantee – Default is no ordering, only the Azure Service Bus supports it native. My natural response would be that ordering is needed, however, it strikes me that it might only be because it is the same assumptions our monolith works under. In any case, if the default is no ordering, TimeLog would need to work with that premise.
- Throughput and latency – With the amount of messages/events I anticipate, then none of these two are an issue. I would probably see the processing being the bottleneck instead.
- Persisted storage – Up to 7 days for Azure Service Bus. I would assume that TimeLog would never need so long, customers expect data to be processed way faster anyway.
- Message size – The lower the better. Azure Service Bus recommends between 10 and 256 KB. It is not for data, it is for messages.
Azure Service Bus seems to be the tool for the job in our case. However, it is important to figure out which characteristics a microservice needs to fulfill to work in this environment. Pulling a bit from the AWS definition: Decentralized, independent, do one thing well and a black box. Additionally, idempotent would also be a nice property especially in a at-least-once delivery model as well as in no-ordering guarantee system.
In the traditionally sense, a microservice handles data/functionality for a particular bounded context. This means that it exposes both reads and writes API endpoints to its consumers. As I mentioned earlier for TimeLog, I don’t see us breaking up the bounded contexts just yet, but we could break functionality and let microservices handle part of the work load. This leads me to this definition:
- Microservice = The actual functionality we need (within a certain bounded context)
- A node = An instance that executes the functionality (multiple nodes doing the same thing should be possible)
This got me thinking that we would need to gradually move into this:
- 1. generation: Calculation-nodes
- 2. generation: Bulk-nodes
- 3. generation: The Real Microservice(tm)
Calculation-nodes requires the type of action and the simple input of an ID of the domain it needs to aggregate or calculate based on. It will fetch the data it needs from the database to do the calculation and manipulate the records the calculation affects. Idempotent at its core. Duplication: Fine. Out-of-order: Fine. Outage: Retry.
Bulk-nodes requires the type of action, a list of IDs to process and parameters for the operation. Like with the calculation-node, it fetches the data it needs and starts performing the necessary action and manipulates the records according to the parameters. Only idempotent if the actual implementation allows it. Duplication and ordering now kicks in as something to consider. There are different options: Adding timestamps to messages, letting the service bus handle it and/or locking data for the application before passing the message to the queue and let the node release the data after it is done.
The Real Microservice(tm) would need a read API and a data store of its own to handle the specific bounded context. At this point, there is no need for me to venture into that.
A final consideration would be for outages and disasters, where I really like the definition by the Azure Team. An outage is the temporary unavailability without data loss. A disaster is defined as the permanent loss of the queue and with potential data loss. In both cases, messages cannot be delivered to the queue and the effect is that data is not updated for the customers. Not an ideal situation. Of course, Azure have geo-replication build-in, but (for me) a even more natural approach is to do a standard try-catch statement and let the catch store the message in a temporary queue in the database and wait for the queue to be back again. The worst-case scenario is that all calculations and aggregations will have to re-executed, but putting in both measures the risk should be very low.
The last structural piece of the puzzle is how the data flows. I like to physically write down notes as I work my way through research and concepts, so I ended up with a drawing like this:
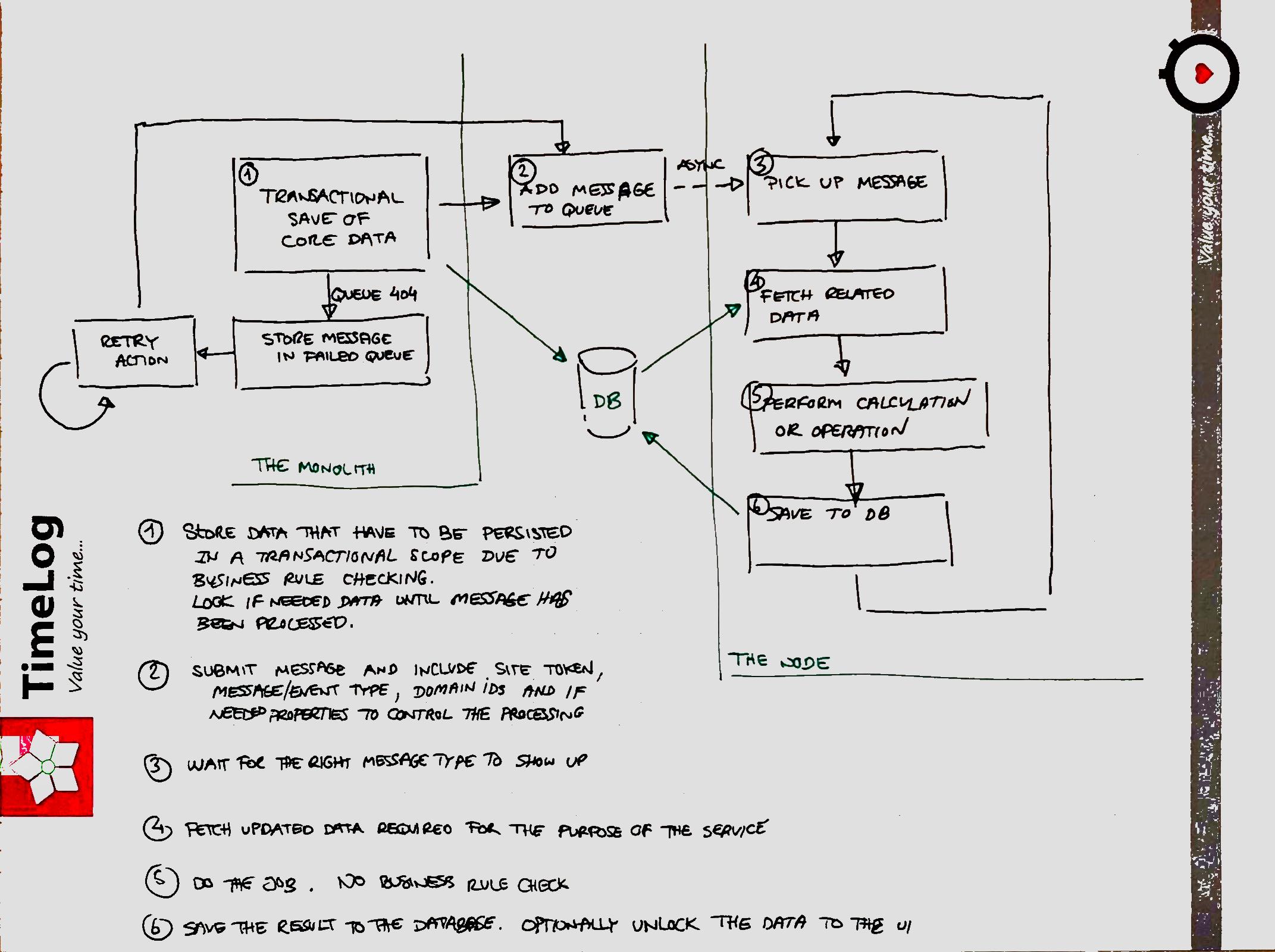
I plan on publishing more about this venture in the future. Let me know if you have questions or feedback on things I have missed.
